
六、网络正则化

原来我
不过是茫茫网络中的一粒神经元而已
——题记
咦?这句话居然有些熟悉……
过拟合现象
很多人听到这个词可能会感到陌生,什么是过拟合?相信很多朋友在做数值回归问题可能会遇到如下现象:
对于下图待回归的数据点:
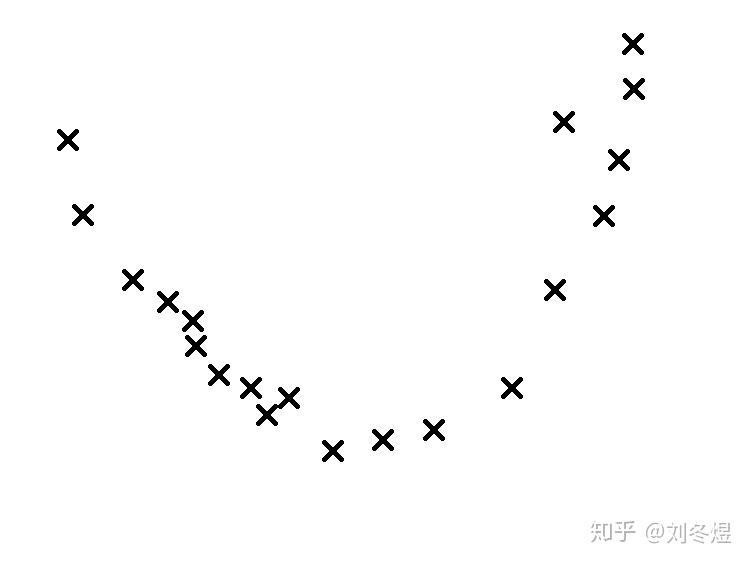

我们知道最适合的曲线是这一条:


但有时训练过度,我们可能会得到这样的曲线:


我们发现,过拟合时,误差函数值确实小于最合适的情况,但这又是我们想极力避免的情况。
不光回归问题如此,分类问题也存在这样的问题。比如下图的二分类问题:
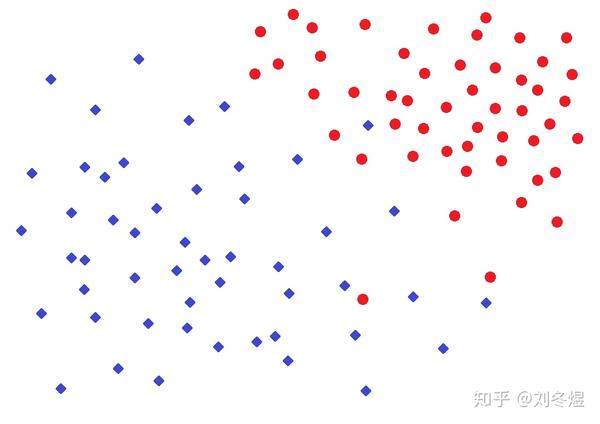

最合适的分法也许是这条曲线:
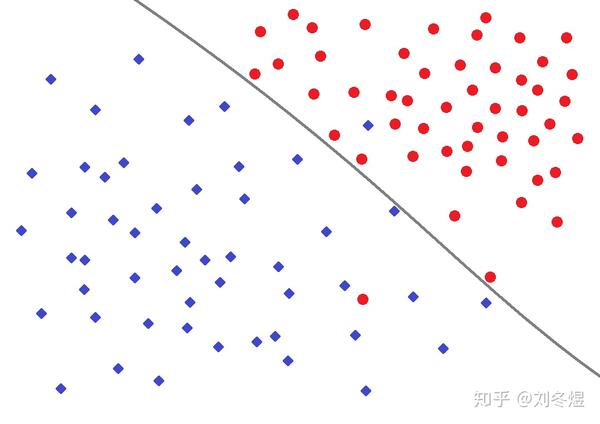

可是,训练过度时,有可能出现这样的曲线:
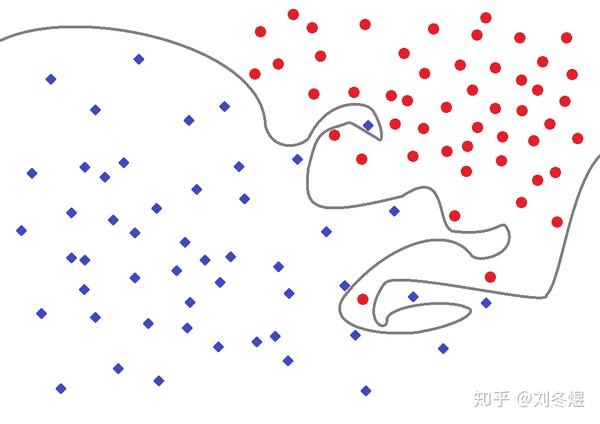

这时很可能出现很多的错误预测,即使你的训练集表现不错。
从误差函数到损失函数
前面我们将误差函数和损失函数两个词混在一起讲,因为这两个函数确实相等。但加入了正则化之后,这两个函数就有了一点点差别:
L(W, b) = E(W, b) + \lambda R(W, b)
即,损失函数等于误差函数加正则化项。
最后计算某一参数\omega的梯度时,将整个损失函数都对其求偏导,即\frac{\partial L}{\partial \omega} = \frac{\partial E}{\partial \omega} + \frac{\partial R}{\partial \omega}。
而正则化项有很多种实现方式,既可以显式地表示成一个函数(如L1范数约束、L2范数约束等),又可以隐式地通过一些引入随机化的诡异骚操作来实现正则化功能(如Dropout、BatchNorm等),亦可以通过缩小解空间来实现(如提前终止、最大范数约束)。
接下来我将对这些正则化方法进行逐一介绍。
L1与L2范数约束
训练神经网络出现过拟合的问题时,原因很可能来自一个参数被训练得很大,直接左右了最终结果。对此,我们想出了一个对策——范数约束。
L1范数约束,即R(W, b) = || W ||_1 + || b ||_1 = (\sum_{i, j}{|W_{ij}|}) + (\sum_{i}{|b_i|})。对某一参数\omega求偏导数的结果为\frac{\partial R}{\partial \omega} = sgn(\omega) = \begin{cases} -1 & \omega < 0 \\ \ \ \ 0 & \omega = 0 \\ \ \ \ 1 & \omega > 0\end{cases}。
而L2范数约束,即R(W, b) = \frac 12 (|| W ||_2^2 + || b ||_2^2) = \frac 12 (\sum_{i, j}{W_{ij}^2}) + \frac 12 (\sum_{i}{b_i^2})。对某一参数\omega求偏导数的结果为\frac{\partial R}{\partial \omega} = \omega。
可以看出,L1和L2范数约束都倾向于将参数的绝对值减少,但L1范数约束更容易让参数减到0,L2范数约束则只是保持了参数减小的趋势。因此L1范数约束更具稀疏性,但L2范数让模型更加简单。
此时,损失函数中的\lambda的值多取10^{-3}~10^{-1}数量级的数。
最大范数约束
最大范数约束和L1、L2范数约束思路一样,最大范数约束也是防止某一参数被训练得过大的正则化方法。不同的是,最大范数约束缩小了解空间,而不是像L1、L2一样提供了参数变化趋势。
最大范数约束的正则项不能显式表示出来,但有明确的算法。首先我们定义M为所有参数构成的向量,当|| M ||_2 \leq c时(即\sqrt{\sum_{i}{M_i^2}} \leq c),不对参数进行多余的变动,但如果|| M ||_2 > c(即 \sqrt{\sum_{i}{M_i^2}} > c ),那么我们要将向量M的范数约束到常数c。方法是,令k = \frac{c}{|| M ||_2}(即k = \frac{c}{\sqrt{\sum_i{M_i^2}}}),然后将网络内每一个参数(权值或偏置量)\omega都乘以这个数k,即可将其范数规约到常数c。
实践中通常将常数c取和参数数量同数量级的数。
随机失活(Dropout)
一个非常玄的正则化方式,依旧无法将其正则项显式表示出来。
其思路是,去除特征中的相互依赖性。比如说,一个人和树的二分类问题,数据集让神经网络得到一个错误的认知:既有胳膊又有腿的是人,否则就是树。于是神经网络在处理实际问题时,很可能把残疾人分到树这一类,也很可能把树杈上挂着只猴子的树分到人这一类。而去除特征的依赖性,则是遇到胳膊、腿、头、脖子等特征时,直接划分到人这一类。遇到树干、树枝、树冠、叶子等特征时,直接分到树这一类。
算法过程是,在训练过程中,将某一层或某几层的每个神经元分别以一个概率p独立地失活——失活代表其输出out = 0。根据链式法则我们知道其不参与到梯度计算之中:
\delta = \frac{\partial E}{\partial net} = \frac{\partial E}{\partial out} \cdot \frac{d\ out}{d\ net} = \frac{\partial E}{\partial out}\cdot 0 = 0
\frac{\partial E}{\partial w^*} = \frac{\partial E}{\partial net^*} \cdot \frac{\partial net^*}{\partial w^*} = \delta^*\cdot out = \delta^*\cdot 0 = 0
也就是说,通过Dropout正则化,我们会从一个原本很“胖”的网络中得到无数个很“瘦”的网络:
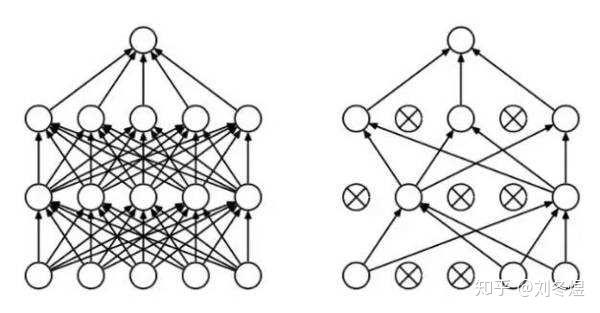

这也是我在题记中提到的,茫茫神经网络,一粒神经元微不足道。Dropout把它抛弃掉,也实属无奈——毕竟要顾全大局。
等待训练收敛后,网络进入生产环境。此时每次传播,所有神经元均保持活动状态,但训练时随机失活的那几层,与后一层之间的边权乘以(1-p),以保证网络实际输出等于训练阶段随机失活时的期望。
虽然算法非常玄,但它是真的猛。Dropout刚被提出时,它还被认为是最有效的正则化方法。
可是,Dropout一旦遇上了ResNet网络模型、BatchNorm层、数值回归问题等之后,就显得非常鸡肋。后来也渐渐淡出了深度学习的舞台。
提前终止
在训练过程中,每训练若干轮跑一遍测试集,如果正确率不变或上升,那么继续训练;否则,即测试集正确率下降,这时终止训练。提前终止可以看做是缩小了解空间的正则化,直接改变了“收敛”位置。
BatchNorm
BatchNorm是悄悄进入人们视野的一种正则化方式。它的思路是,一次性随机跑多个样本,在某些层激活之前,将其归一化(也称“白化”),然后再通过激活层激活。由于激活函数对这一区间的数相对更敏感一些,所以这能够使得激活函数的非线性特征充分发挥。关于BatchNorm层内的具体计算,我将在后面介绍。
正则化的意义
正则化,顾名思义,就是对于我们求解的参数的一个约束。通过正则化,可以改变收敛位置,一定程度上提高网络泛化能力。
究竟如何改变收敛位置的呢?以L1、L2范数约束为例,如果我们开一个比较小的正则化值,也许收敛时参数的值有轻微移动:
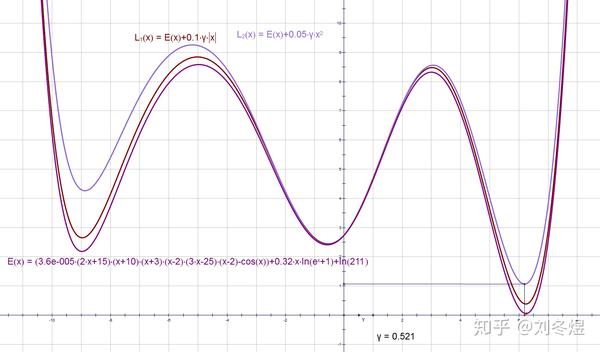

而选取一个较大的正则化因子,原先的最小值甚至有可能变成局部最小值,收敛位置可能发生巨大的改变:
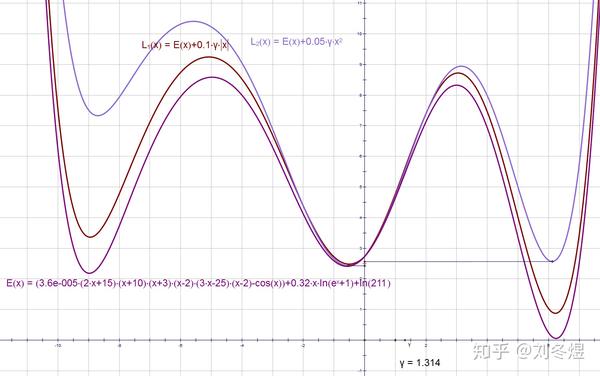

Dropout和BatchNorm等更不必说了,造成的差距将会更加之大。
但正则化只是引领了一个经验上的方向,究竟采用什么正则化,是否采用正则化,也是一个超参数,需要调参得到。
感谢您的阅读。限于笔者水平,文章定有疏漏。如有不足,敬请斧正!
文章被以下专栏收录
