切换模式

决策树(一)熵、条件熵、信息增益

黑夜不再来
学生
Email:ht0909@ mail.ustc.edu.cn
原创内容,转载请标明
参考:《统计学习方法》李航
一.熵、条件熵、信息增益
- 熵(entropy)
熵表示随机变量不确定性的度量。


熵越大代表随机变量的不确定性就越大。
- 条件熵(conditional entropy)


当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。
经验条件熵就是在某一条件约束下的经验熵。
- 信息增益(information gain)
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。


一般地,熵H(Y)与条件熵H(Y|X)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
决策树学习应用信息增益准则选择特征。给定训练数据集D和特征A,经验熵H(D)表示对数据集D进行分类的不确定性。而经验条件熵H(D|A)表示在特征A 给定的条件下对数据集D进行分类的不确定性,那么它们的差,即信息增益,就表示由于特征A而使得对数据集D的分类的不确定性减少的程度。不同的特征往往具有不同的信息增益,信息增益大的特征具有更强的分类能力。
算法1.(信息增益算法)






二.计算信息增益实例
- 例
表5.1是一个由15个样本组成的贷款申请训练数据。数据包括贷款申请人的4个特征(属性):年龄、有无工作、有无房子、信贷情况。表的最后一列是类别,是否同意贷款。
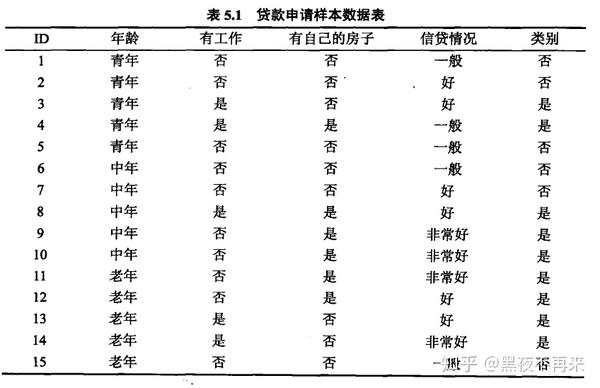

希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。




发布于 2018-08-02 17:31
决策树
熵