神经架构搜索(NAS)2020最新综述:挑战与解决方案

A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions
- 2021.1.18:该文章经过多轮修改以正式被ACM Computing Surveys录用
终于把这篇NAS最新的综述整理的survey放了上来,文件比较大,内容比较多。这个NAS的survey是A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions
的写作过程中的整理的原材料,文章目前孩还在审稿阶段可以预览。相关报道:
别外,由于知乎的.md文件表格上传格式过于难调,也推荐大家阅读github上关于近年NAS的idea整理。
也可以查看CSDN,对表格支持的不错。
相关截图如下:




下面是其中一部分论文的概要总结,建议主要参看下面的部分。github图片显示有问题。相关参考的博客网页如为尽数引用还请见谅。内容较多,未能准确表述之处还请指正。谢谢
Paper Details
RL在NAS上开创性的两篇工作
NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING (ICLR'17)
使用强化学习的一个NAS的开创性工作
将NN网络模型的描述表述为一系列变长的string,使用RNN作为控制器来生成这种string
RL与NAS 的结合
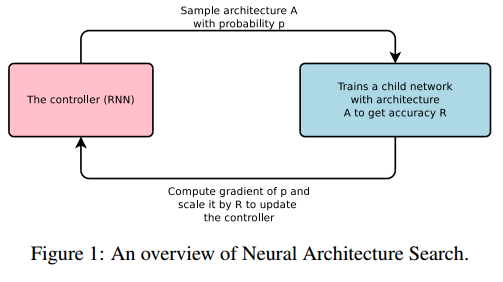

- controller(RNN):相当于agent,生成框架A(相当于做出一个动作)
- 蓝色框:相当于是一个环境E,对动作做出反馈,即当前框架A的acc作为reward
- 调整controller:将acc作为反馈信号,调整controller,做出新的动作
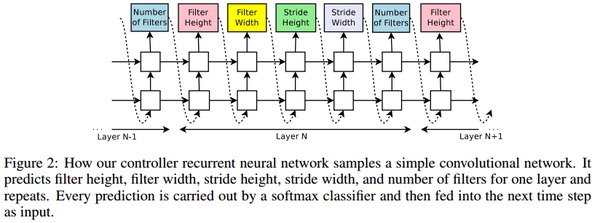
使用RNN控制器生成模型框架的参数:
- 包括kernal size, step, channel
- 上一个RNN生成的参数作为下一个RNN的输入

RNN控制器参数的更新
通过更新控制器RNN的参数θ来调整生成的模型框架


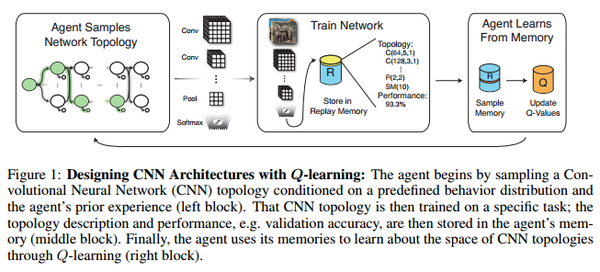
DESIGNING NEURAL NETWORK ARCHITECTURES USING REINFORCEMENT LEARNING (ICLR'17)
将框架的选择视为一个马尔卡弗决策的过程,使用Q-learning来记录奖励,获得最优的网络框架
Designing CNN Architectures with Q-learning
使用RL进行NAS的整体的流程:
- 预定一个整体的网络框架
- 从中采样一个网络的拓扑结构
- 将拓扑的信息和性能表现进行存储
- angent通过Q-learning,利用自己的memory学习CNN的拓扑

Q-learning中Q值的更新
https://www.jianshu.com/p/dc79f9e43a1d


Markov Decision Process for CNN Architecture Generation
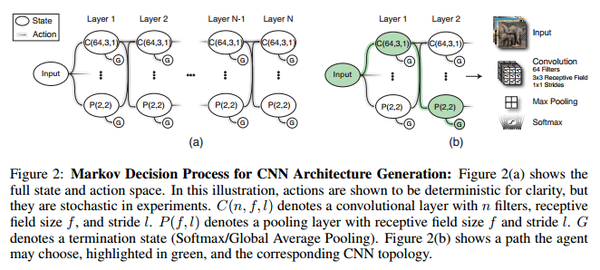

此方法也是非常耗时,对于每个数据集,作者使用10块GPU训练了8-10天。
When NAS Meets Robustness: In Search of Robust Architectures against Adversarial Attacks (2020CVPR)
Abstract
是为了寻找健壮鲁棒的深度网络模型,采用NAS的方法生产大量可用于评估的网络框架。
Our “robust architecture Odyssey” reveals several valuable observations:
1) densely connected patterns result in improved robustness; 密集连接有助于提升网络模型的鲁棒性
2) under computational budget, adding convolution operations to direct connection edge is effective;计算资源有限的情况下,直连边的卷积操作是有效的,相较下的是跳跃连接。
3) flow of solution procedure (FSP) matrix is a good indicator of network robustness.
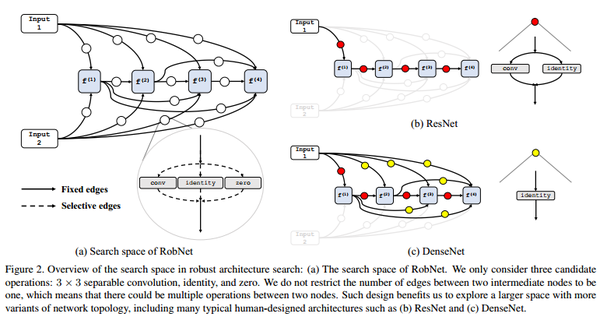
Search Space
基本沿用和DARTS相似的有向无环图的设计思路:
- 每个cell将前两个cell 的输出作为输入
- cell的输出等于cell内中间节点的拼接
不同的是:
- 不在限制两个节点之间的连接个数(即操作数),增加可供搜索的architecture的丰富度;
- 没有看到不同操作的权重赋值,而是直接对其进行了加和。搜索方法采用的是典型的one-shot model 的方法。

cell-based的architecture鲁棒性分析


(a)对supernet进行PGD的对抗性训练,采样1000个子网络,在验证集微调前后的性能对比,对子网络进行对抗性微调有助于性能的提升(更加具有针对性)
(b)绘制微调后子网络的性能直方图,猜测鲁棒性好的网络框架拥有相似的网络结构
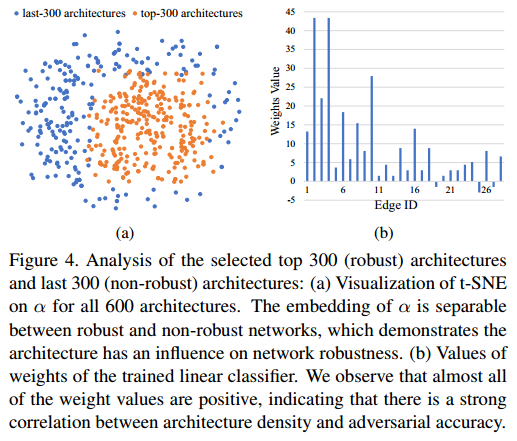

(a)对robust和non-robust的框架参数α使用t-SNE进行降维可视化,发现二者明显可分。
(b)使用一个线性分类器对这个600个框架进行分类的权重进行可视化,权重几乎都为正数,表明框架的连接密度对健壮性有很强的相关性。
于是进一步定义框架密度D,并探究其与模型的健壮性之间的关系:

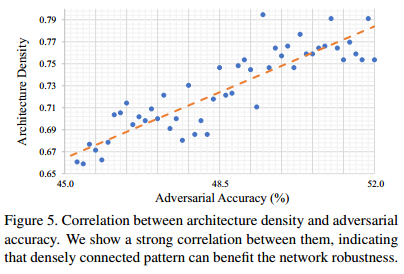
以此说明密集连接有助于提升框架的鲁棒性。
Understanding and Simplifying One-Shot Architecture Search (2018ICML)
Example of a cell during one-shot model evaluation
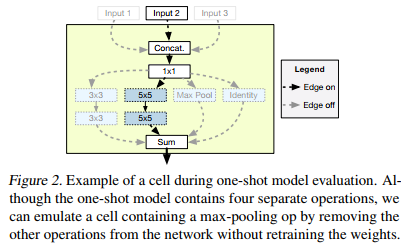
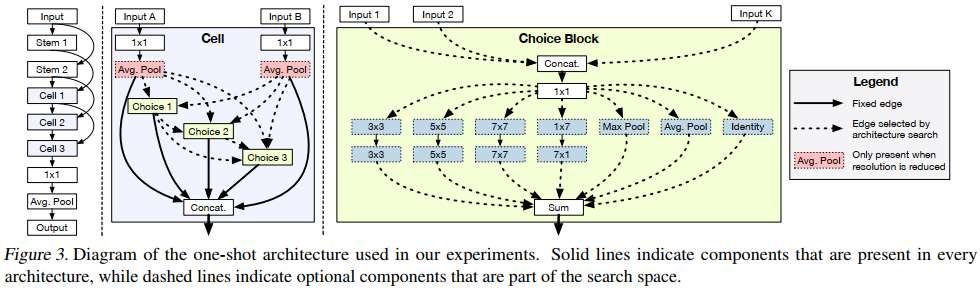
Diagram of the one-shot architecture

Understanding One-Shot Models
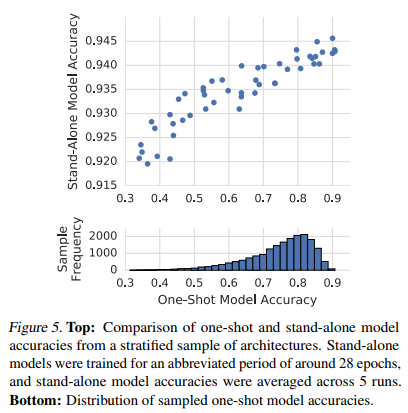
当我们从stand-alone转向one-shot model时,虽然最佳模型的准确性仅下降5 - 10个百分点,但前景较差的架构的准确性下降了60个百分点。
作者认为神经网络架构搜索能够找到哪些操作是有效的,如果这些有效操作存在于模型中,那么就可以预测这些架构的准确率很高,如果他们不存在模型中,所以就预测他们的准确率很低。
Removing the less important operations from the network has relatively little influence on the model’s predictions and only a modest effect on its final prediction accuracy.
Removing the most important operations from the network, however, can lead to dramatic changes in the model’s predictions and a large drop in prediction accuracy.
为了验证上述实验的假设,作者设计了一个新的实验:
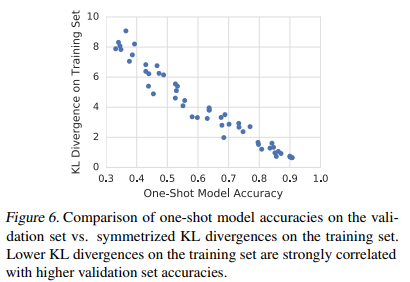
使用对称的KL散度来评估搜索出的模型和ALL ON模型(即保留大量路径基本不削减)的预测分布,结果如下图所示。作者发现,表现好的One-Shot模型和ALL ON模型的对称KL散度低,即这两者的预测很接近,这些One-Shot模型的验证集准确率也高。作者认为这表明权重共享会使得One-Shot模型专注于最有效的操作.
Population Based Training of Neural Networks (2017)
提出了一种新的超参数的优化方法:结合并行搜索与序列优化进行探索最有的超参数。
PBT与SO和PS的对比示意图
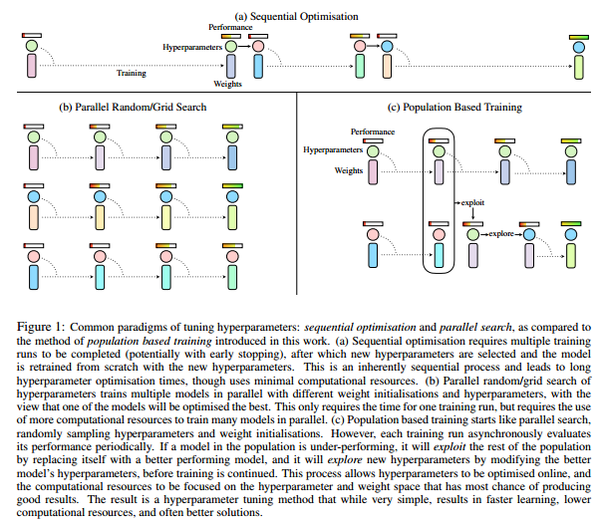

如图所示,(a)中的序列优化过程只有一个模型在不断优化,消耗大量时间。(b)中的并行搜索可以节省时间,但是相互之间没有任何交互,不利于信息利用。(c)中的PBT算法结合了二者的优点。 首先PBT算法随机初始化多个模型,每训练一段时间设置一个检查点(checkpoint),然后根据其他模型的好坏调整自己的模型。若自己的模型较好,则继续训练。若不好,则替换(exploit)成更好的模型参数,并添加随机扰动(explore)再进行训练。其中checkpoint的设置是人为设置每过多少step之后进行检查。扰动要么在原超参数或者参数上加噪声,要么重新采样获得。
PBT的伪算法
θ:当前框架的可训练的参数
h:当前框架的超参数,相当于确定了模型的框架结构
p:性能评价
t:训练的步骤数


效果展示
- GAN & RL 左边的gif是GAN在CIFAR-10上的效果,右边是Feudal Networks(FuN)在 Ms Pacman上的效果。
图中红色的点是随机初始化的模型,也就是所谓的population。再往后,黑色的分支就是效果很差的模型,被淘汰掉。蓝色的分支表示效果一直在提升的模型,最终得到的蓝色点就是最优的模型。不得不说,DeepMind这可视化效果做的,真的强。
Efficient Architecture Search by Network Transformation (AAAI'18)
不再从零开始对网络进行搜索和训练,基于net2net的net transformation对现有的网络进行修改,使用RL来决定要采用哪种transformation操作
Overview
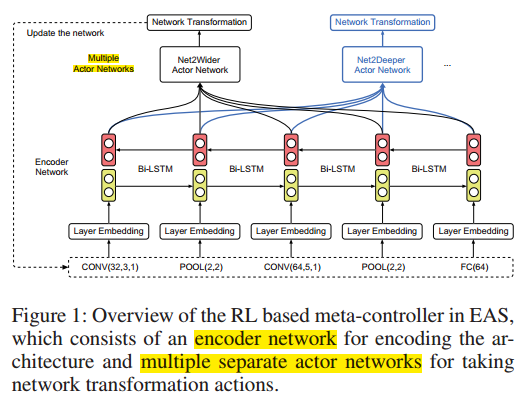

主要包括:
- 对现有网络架构进行编码的encoder network,获得体系结构的低维表示
- 决定采用哪种transformation action类别的多actor networks
Actor Networks
Net2Wider Actor
Net2Deeper Actor
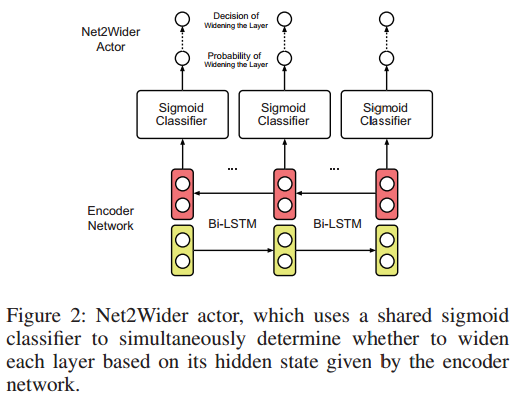

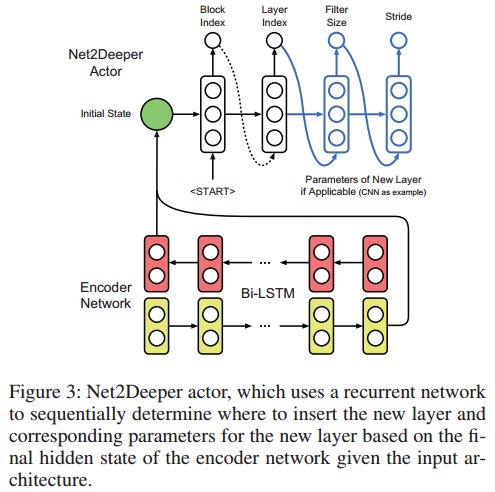
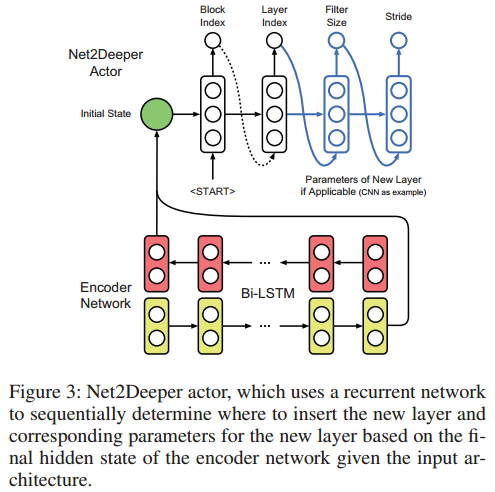
- Net2Wider Actor:用来决定是否对网络的每一层进行扩展
- Net2Deeper Actor:决定是否对网络继续加深,即插入层数的位置与插入层的尺寸
N2N learning: Network to Network Compression via Policy Gradient Reinforcement Learning (ICLR'18)
使用RL的方法来压缩网络模型,主要包含两个操做:
- 移除层
- 压缩层参数
Overview
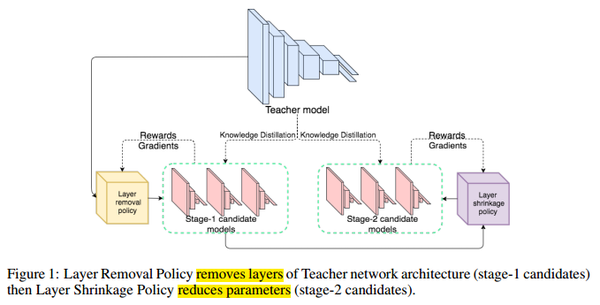

通过一个两阶段的方法来压缩网络模型:
- first selects a macro-scale “layer removal” action,宏观角度上的层移除
- followed by a micro-scale “layer shrinkage” action,微观角度上的层压缩操作
最后使用知识蒸馏的方法来训练产生的候选网络。
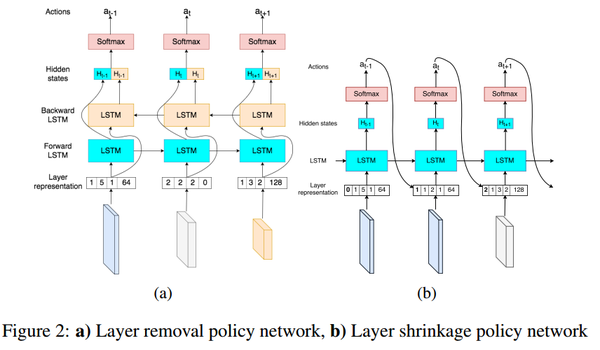
两个阶段所采用的网络结构

结果
ResNet-34上实现了10倍的压缩。
A FLEXIBLE APPROACH TO AUTOMATED RNN ARCHITECTURE GENERATION (ICLR'18,MIT)
用来自动化生成RNN框架。
本文来自 MIT 和 Salesforce Research,论文提出了一种用于循环神经网络灵活自动化架构搜索的元学习策略,明确涵盖搜索中的全新算子。该方法使用了灵活的 DSL 搜索和强化学习,在语言建模和机器翻译等任务上表现良好。新方法可以让我们摆脱依靠直觉的费力模型设计方式,同时也大大扩展了循环神经网络的可能性空间。 ———————————————— 版权声明:本文为CSDN博主「PaperWeekly」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/82786338
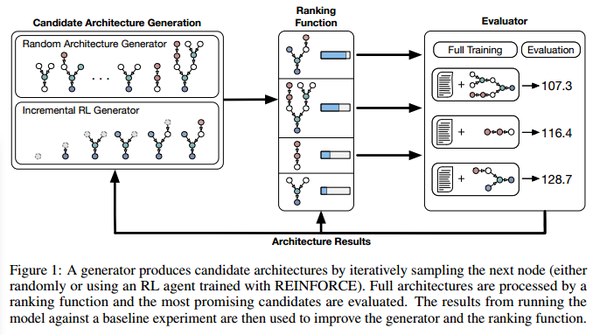

- 迭代采样下一个节点生成候选网络(采用随机策略或者RL)
- 排序函数通过RNN处理每个候选体系结构的DSL,预测体系结构的性能
- 最有希望的候选框架被评估
- 根据评估结果改进框架生成器和排序函数
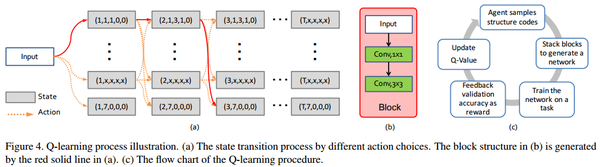
Practical Block-wise Neural Network Architecture Generation (CVPR'18)
- 任务:使用RL的Q-learning策略训练代理,自动化生成基于block的网络框架
- 优势:基于block,大大减小了搜索空间,降低了搜索的计算量
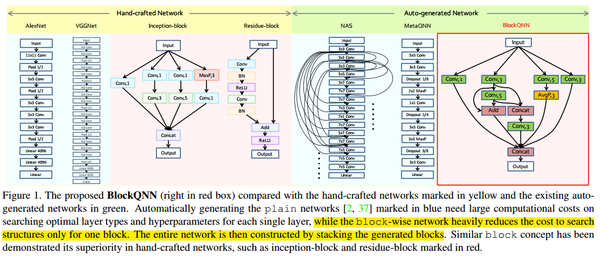
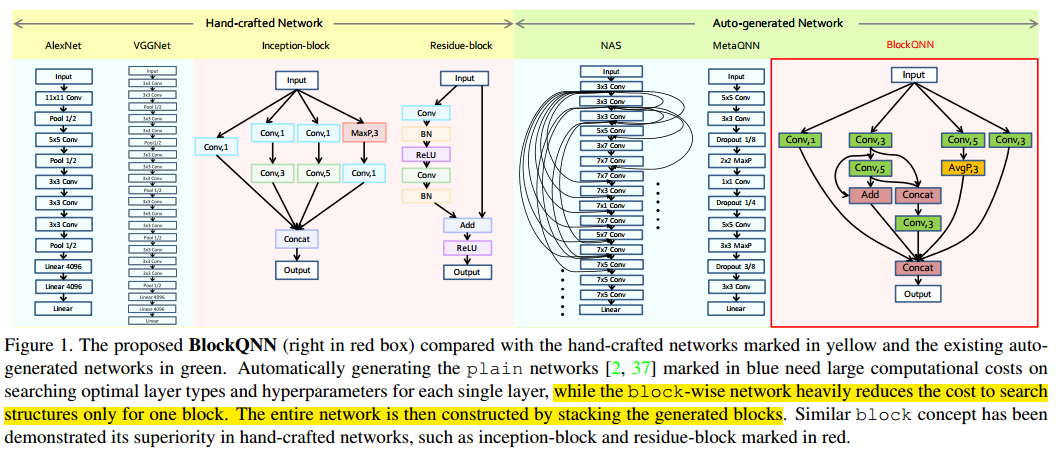
BlockQNN与手工网络和其他自动化生成网络框架之间的对比图
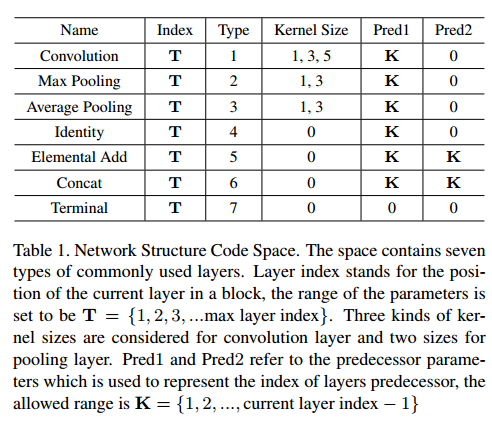
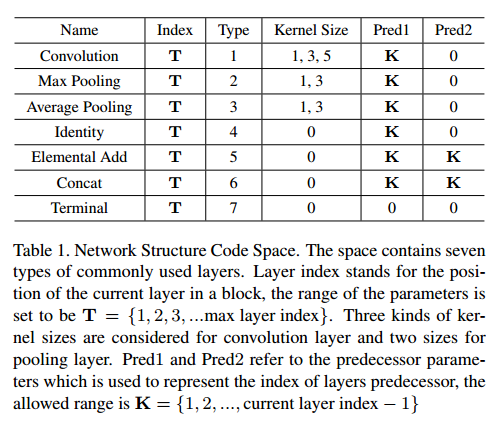
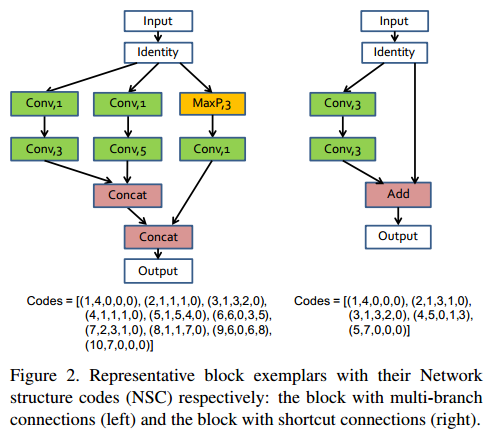
框架编码
Network Structure Code Space
NSC示例

Q-learning process illustration

Q-learning学习的有效性
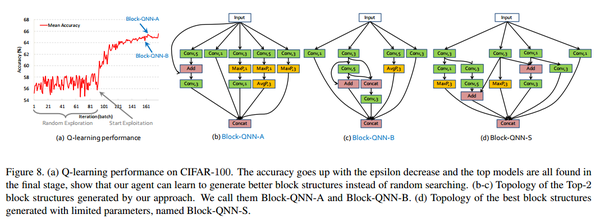

- (a)随机探索与Q-learning搜索的对比
- (b)、(c)Top2的结构
- (d)有参数限制下的最佳结构
Path-Level Network Transformation for Efficient Architecture Search(ICML'18)
基于已有的网络,重用模型,重用权重对连接上的路径级别进行修改
Efficient Architecture Search by Network Transformation主要是对层级别的网络进行修改,本篇文章主要对路径级别的网络进行修改
可参考解读文章: Path-Level Network
Path-Level的架构搜索
为什么要做Path-Level的架构搜索?
因为已经有一些Multi-Brach Neural Networks取得了很好效果,我们需要提供一种方法可以改变旧网络的拓扑结构,使得我们有机会生成表征能力更强的类似Inception models, ResNets这样优秀的网络或更好的网络。
定义如何拓宽网络 Net2WiderNet
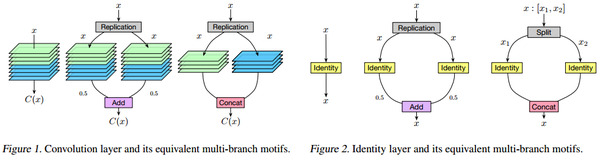

定义两种操作,Replication-Add和Split-Concat:
- Replication-Add是指将x复制成2份,分别操作后把结果除以2再相加,保证输入和输出和之前的维度相同。
- Split-Concat是指将x按照维度切成两份,分别操作后再把结果相接,保证输入和输出和之前的维度相同。
定义如何加深网络 Net2DeeperNet
利用Net2DeeperNet在当前层后面加一个identity层(实现细节可以看论文中的相关链接Net2Net)
定义Path-Level的架构搜索的数据结构
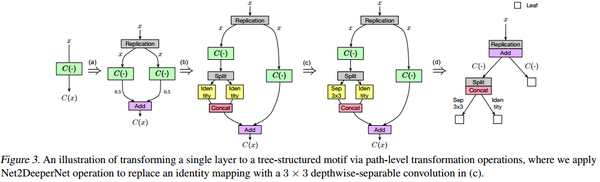

- a过程是Net2Wider的过程,
- b过程是Net2Deep后再Net2Wider的过程,
- c过程是对其中的层替换的过程,
- d过程是把c过程定义成了我们的树结构
- 节点:分配和合并策略,边:层 由此,我们可以把整个过程看做是一个在树上搜索的过程。
搜索
类似于Layer-Level的思想,但我们利用lstm来决定用哪一层,用Tree-lstm来决定我们该使用什么分配合并策略,最终完成Layer-Level的搜索,我们不难发现Tree的结构是节点和边交替出现的,所以Tree-lstm的输入是前一个lstm的输出,Tree-lstm的输出是后一个lstm的输入。
HIERARCHICAL REPRESENTATIONS FOR EFFICIENT ARCHITECTURE SEARCH (ICLR'18,CMU&DeepMind)
提出了一种层次化的神经网络搜索空间,并通过进化算法进行搜索
参考: https://blog.csdn.net/dhaiuda/article/details/95722971
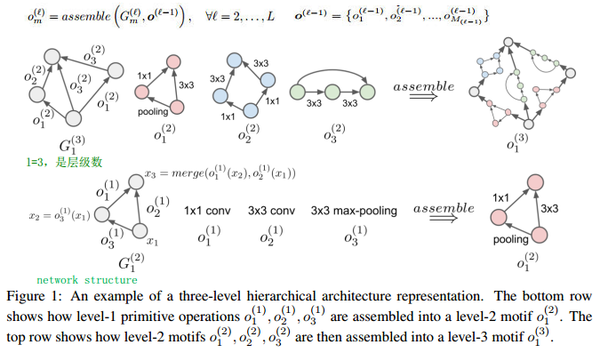
hierarchical architecture representation 分层框架表示
G是一个net的有向无环图,节点是feature map,边是对应的操作,该操作不再是简单的卷积,而可以是低一级G(有向无环图的操作)

进化算法
种群初始化
具体步骤如下:
- 定义分层架构的层数,定义每层计算图的形状,定义第一层基础操作集
- 初始化一批种群个体,个体中的每个cell都是直接映射,即输入等于输出
- 对种群中的个体进行大规模的变异操作
变异操作
具体步骤如下:
- 随机选择一层,随机选择该层的一个计算图,随机选择该计算图的一个顶点i
- 随机选择该计算图顶点i的后继结点j
- 从基础操作集中随机选择一个操作替换现有操作,如果结点i与结点j不存在操作,此时相当于添加一条由结点i指向结点j的有向边
- 上述步骤可以实现添加一条有向边,去除一条有向边,更改一条有向边对应的操作等
选择
- 采用锦标赛选择算法,每次选出当前种群中5%的个体,
- 选择适应度(在验证集上的准确率)最高的个体,对其进行变异操作后产生新个体,新个体在训练一定轮数并计算适应度后放回种群中,
- 论文采取的锦标赛算法不会kill掉任何个体,随着算法的运行,种群的规模会不断增大
随机搜索
随机搜索即去除掉锦标赛算法后的进化算法,即随机选择个体,随机进行变异操作
算法的超参数
初始种群个数N 分层架构的层数L 每一层基础操作集中操作的个数 每一层的计算图架构
预先定义好的网络整体框架
cell是通过学习得到的结构
- small:用于搜索阶段的框架比较
- large:用于评估学习的cell


Neural Architecture Optimization (18'NeurIPS)
以往的基于RL和EA的方法多是在离散的搜索空间上搜索最优的框架,这是非常低效的.本文提出将网络模型通过编码器进行连续化,通过预测方程选出最佳的网络表示,再通过解码器将框架的连续表示进行离散化.
可参考
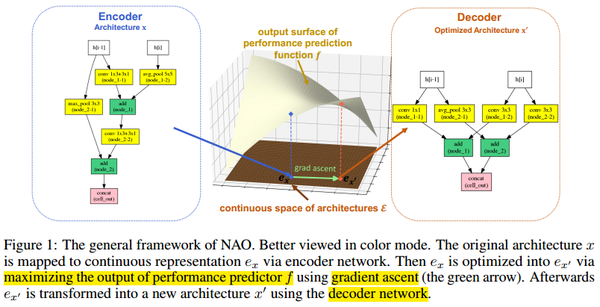

- 编码器: 将离散的网络框架进行编码为一个连续的表示
- 预测方程: 将连续的表示作为输入, 预测模型的性能
- 解码器: 将选择出来的网络框架的连续化表示进行解码离散化
Progressive Neural Architecture Search (ECCV'18)
学习cell结构, 从简单到复杂的方式渐进地学习一个cell结构, 通过拼接得到最终的模型, 对于候选模型的评估采用学习的预测函数进行预测, 得到候选模型的排序
可参考: https://blog.csdn.net/weixin_41943637/article/details/102155844
Cell(5blocks) & Architecture
cell中包含5个block,每个block有一个五元组组成(I1, I2, O1, O2, C) :两个输入,两个对应的操作,一个合并的操作类型
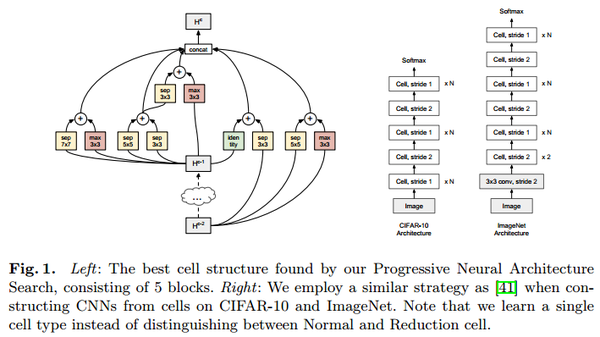

递增式cell的构建
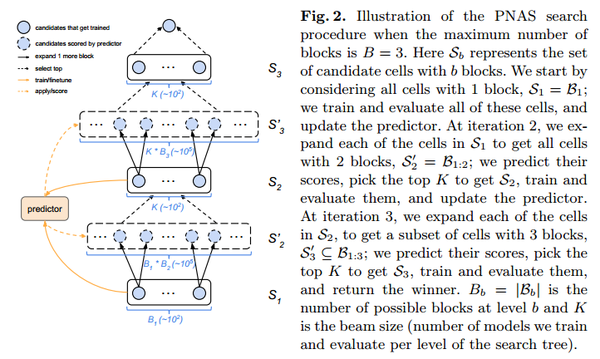

- 蓝色的小圆圈:一个对应的框架
- 黑色实线箭头:添加一个block
使用代理模型预测性能


Large-Scale Evolution of Image Classifiers (ICML'17)
使用EA算法尽可能减少人为干预的情况进化到一个具有好的性能的网络框架
可参考: https://blog.csdn.net/mynodex/article/details/96589377, https://blog.csdn.net/dhaiuda/article/details/95587258
需要注意的几点:
- 变异过后weight的形状如果没有改变,子框架可以继承父代框架的权重,禁用权重继承性能会有所下降
- 没有将在小的数据集上得到的模型直接推广到大的数据集上,而是分别进行搜索评价
进化的实验过程
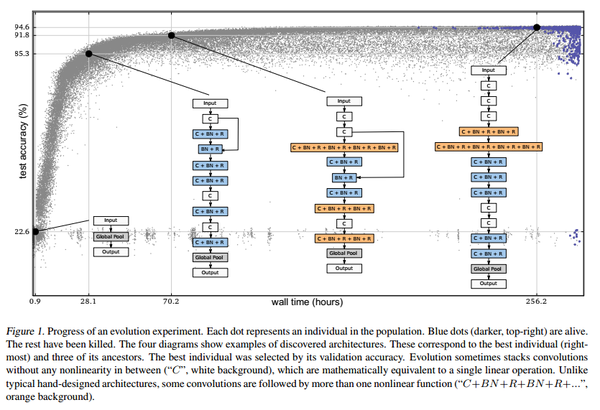

上面的每个点都表示一个individual,其中灰色的点是被杀死的点,蓝色的点是存活下来的点。底下的四个框架是演变过程的一个例子。一开始的时候网络只有一个全局池化层,通过演变一步步变为最后的结构。从结构可以看出来,和人工设计的网络结构不同,这些网络结构有时会经历很多个非线性激活层。 ———————————————— 版权声明:本文为CSDN博主「mynodex」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接: https://blog.csdn.net/mynodex/article/details/96589377
进化算法/禁用权重继承的进化算法/随机搜索的性能对比
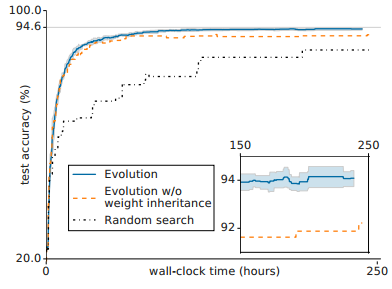

禁用权重继承性能会有所下降
Genetic CNN(ICCV'17)
通过遗传算法进行神经网络架构搜索,论文首先提出了一种能表示神经网络架构的编码方案,在此编码方案上初始化种群,对种群进行选择、变异、交叉,从而抛弃性能差的神经网络架构并产生新的神经网络架构,论文将训练好的架构在验证集上的准确率作为评判网络性能好坏的指标
可参考: https://blog.csdn.net/dhaiuda/article/details/95477009
遗传算法简介
传统的遗传算法往往具有下列步骤:
- 定义个体的基因编码方案
- 初始化种群
- 衡量个体生存竞争能力的适应度(通常是一个函数,函数值表示个体的生存竞争能力)
- 淘汰适应度低的个体,选择适应度高的个体构成种群下一代的成员(选择)
- 按一定概率对下一代成员进行基因的交叉与变异(交叉与变异),产生新个体的基因编码方案
- 评估新种群的适应度
可以看到,遗传算法其实就是模仿生物进化的过程
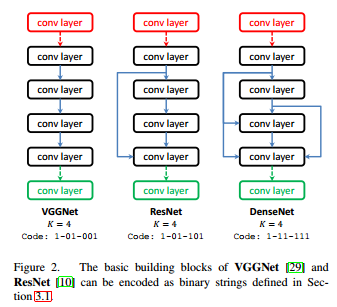
框架的编码示例
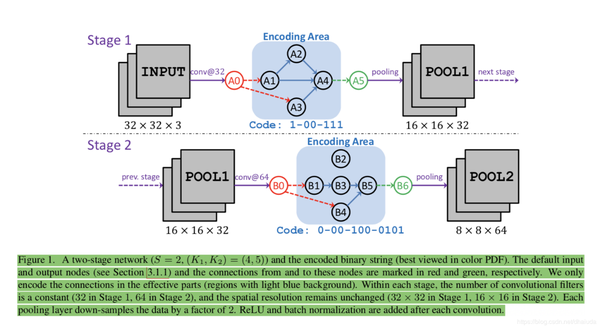

为了让每一个编码均有效,论文在每个阶段中额外定义了两个默认节点,对于第s个阶段来说,分别为上图中的红色和绿色节点,
- 红色节点接收前一节点的输出,对其进行卷积,并将输出的特征图送往所有没有前驱但是有后继的节点,
- 而绿色节点接受所有有前驱但是没后继节点输出的特征图,对其进行element-wise相加后,输入到池化层,这两个节点不做编码
- 如果一个阶段的编码为0,则红色节点直接和绿色节点连接,即经过以此卷积操作后立刻进行池化操作。
该论文也是选择在小数据集上探索网络架构,在将探索到的网络架构应用于大数据集.
网络编码示例
两个独立进化得到的网络框架
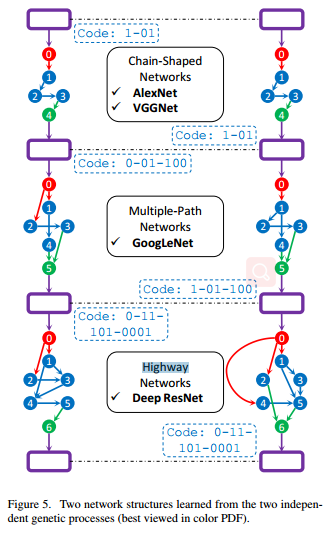
其他细节可参考: https://blog.csdn.net/dhaiuda/article/details/95477009
FAST NEURAL NETWORK ADAPTATION VIA PARAMETER REMAPPING AND ARCHITECTURE SEARCH(ICLR20)
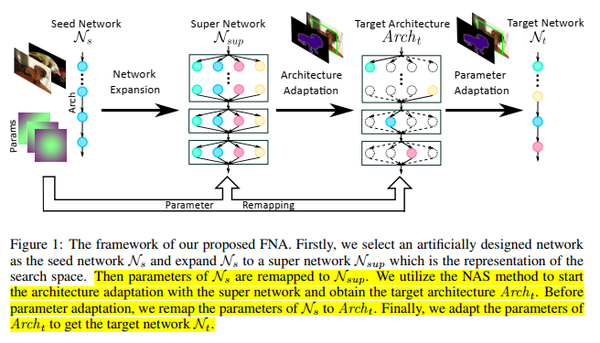

从一个设计好的人工网络开始,对其进行拓展得到super network,然后做架构自适应得到目标架构,然后做参数自适应得到目标网络。
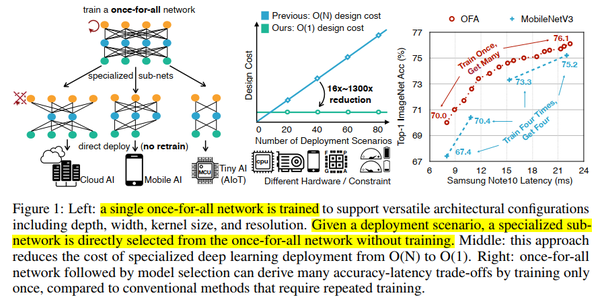
ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPECIALIZE IT FOR EFFICIENT DEPLOYMENT ON DIVERSE HARDWARE PLATFORMS (ICLR20)
将模型训练从架构搜索中解耦出来,来实现一次训练,挑选子网络进行不同平台的部署。
子网络之间相互共享权重,为了避免子网络之间相互影响,提出渐进收缩算法。
可参考

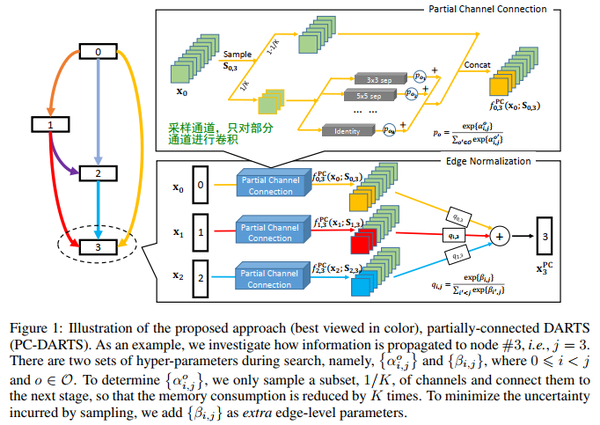
PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search(ICLR20)
为了减少内存的消耗,对通道进行采样(1/k),只对部分通道进行卷积.
边正则化:缓解上述的“部分通道连接”操作会带来一些训练不稳定的问题
可参考